Transforming News Archives into an Interactive Knowledge Base
Transforming News Archives into an Interactive Knowledge Base
At PARKA, we recently partnered with a prominent regional newspaper to help them leverage decades of local journalism in the digital age.
This post details our journey of building a Retrieval-Augmented Generation (RAG) system that transforms their vast archive into an interactive knowledge base accessible to the community.
The Purpose
Our goal was to make sense of their vast repository of unstructured data and transform it into a searchable tool, enabling community members, researchers, and historians to easily access information about their region.
The process follows this outline:
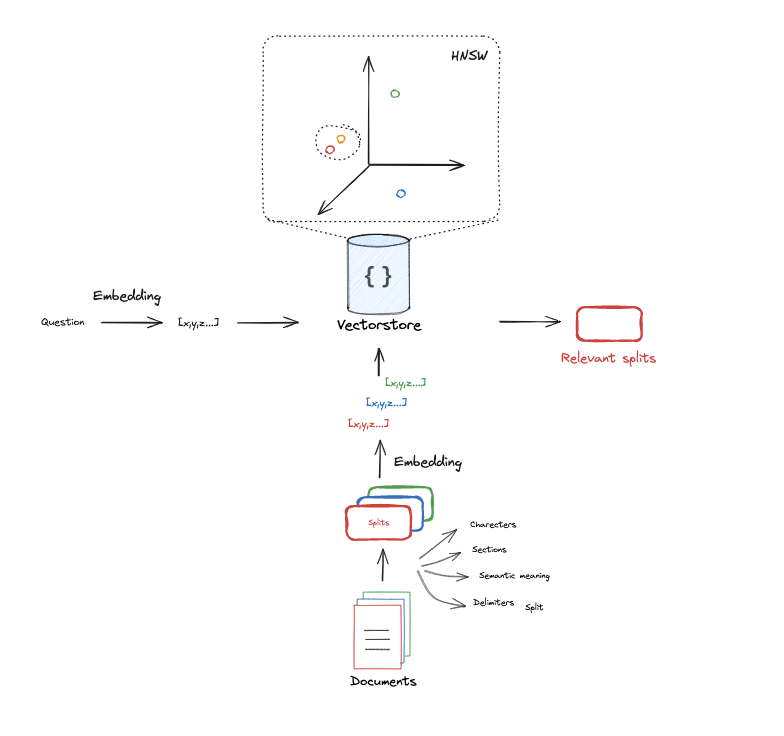 Source: LangChain RAG From Scratch
Source: LangChain RAG From Scratch
- Parse all news content and transform it into vectors:
This process, called embedding, uses an AI model to position each article in a vector space. The position of articles in this space later allows us to compare the semantic similarity between user questions and news content.
- Index all news and knowledge into a vector database:
After parsing all documents and defining their positions in the vector space, we store them in a specialized vector database. These databases offer built-in methods to retrieve and semantically compare files, allowing us to:
- Find the n most similar documents to a given document
- Calculate similarity scores between documents
- Perform other semantic comparison operations
- Retrieve relevant documents based on user prompts:
We embed user prompts into the same vector space, then retrieve the documents positioned closest to them semantically.
- Build the final prompt to feed the LLM:
With the key components in place, we can process user queries by including the semantically meaningful documents as context within the prompt, using a structure like:
# Example prompt template prompt = """ Answer the question based only on the following context: {context} Question: {question} - Generate responses:
With additional semantically relevant information provided, the LLM uses this context to formulate accurate answers for the user.
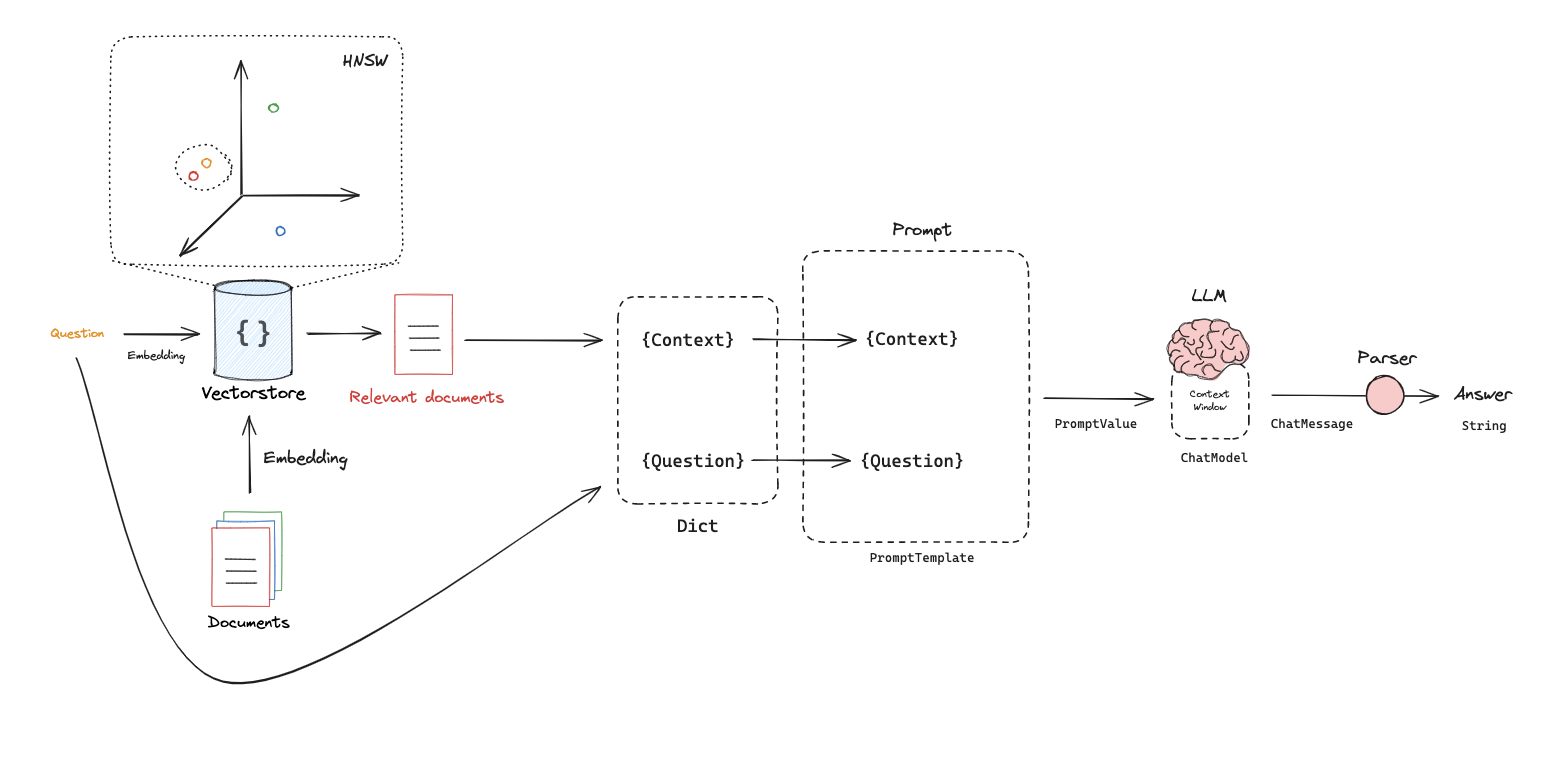 Source: LangChain RAG From Scratch
Source: LangChain RAG From Scratch
Our Technical Approach
We’re building this RAG tool using exclusively open-source technologies:
- Models are served by Ollama, and we’re currently testing several options:
- Llama 3.3 - Meta’s latest open-source LLM
- Deepseek R1 - A powerful reasoning-focused model
- QwQ - Alibaba Cloud’s efficient multilingual model
All running on infrastructure provided by our colleague Igor Marques.
- The pipelines are built with LangChain and monitored with LangSmith
- Deployment is handled with FastAPI
- Open WebUI serves as the chat interface with the model
Conclusion
This RAG implementation represents a significant step forward for our newspaper partner. By transforming decades of local journalism from static archives into an interactive knowledge base, we’re helping preserve and enhance the accessibility of valuable regional information.
The benefits extend beyond simple information retrieval:
- Preserving local history: Important community stories become searchable and remain relevant for future generations
- Enhancing research capabilities: Historians and researchers can quickly find connections across decades of reporting
- Serving the community: Residents gain an intuitive way to access information about their region’s past and present
This project demonstrates how open-source AI tools can breathe new life into existing content archives. As we continue refining the system, we’re focused on improving accuracy, enhancing the user interface, and potentially expanding the types of content that can be included in the knowledge base.
For news organizations sitting on valuable archives of content, RAG systems offer a practical way to unlock that value while providing a new service to readers and communities.
Further Reading
- Build a Retrieval Augmented Generation (RAG) App - LangChain’s official tutorial on RAG implementation
- Building a Local RAG System - Step-by-step video tutorial on creating Local RAG systems
- LangChain RAG Templates - Sample implementations to accelerate development