Managing machine learning lifecycle with MLFlow - Script
Introdução
Bom dia a todos, É um prazer estar aqui no TDC falando com vocês, essa é a primeira palestra presencial que eu dou então espero que vocês curtam, meu objetivo aqui é deixar vocês com vontade e um norte para criar pipelines de inteligência artificial robustos, escaláveis e performáticos. Minha ideia aqui é apresentar um protótipo de uma pipeline que independente da indústria de atuação pode ser considerada sólida, eu atualmente trabalho numa startup aqui de florianópolis chamada BoletoFlex, nós concedemos crédito para pessoas que não tem acesso pelos bancos tradicionais ou não pode onerar o limite do cartão de crédito com gastos em bens de consumo duráveis. Isso na prática significa que somos uma instituição financeira que concede crédito a partir do varejo, estamos presentes como forma de pagamento no checkout da mobly, da cvc, da ame e diversas outras lojas.
E assim como toda instituição financeira que utiliza modelos de inteligência artificial, nossos erros de modelagem podem custar muito caro e dependendo do grau de dependencia da empresa nos modelos, erros podem quebrar uma instituição, seja elevando nível de inadimplência, não identificando fraudes corretamente, e etc.
Portanto eu vou apresentar uma solução conceitualmente simples, mas que a partir dela é possível extrapolar para praticamente qualquer caso de uso, eu vou trazer um exemplo de arquitetura e algumas ferramentas que podem auxiliar na construção de todas as etapas de um projeto de machine learning, e tornar o ciclo de vida desse modelo virtuoso, em que a cada retreino periódico que for fazer eu não precise construir tudo do zero, e a cada a iteraçao ele melhore. E a gente só precise matar esse modelo e fazer outro quando ele não fizer mais sentido existir.
Falando de MLOps
Bom, para iniciar a minha apresentação eu quero trazer alguns conceitos fundamentais do tema que iremos tratar, e preciso admitir que fiquei muito surpreso quando olhei o cronograma da trilha e eu seria o unico que falaria sobre MLOps, eu já tinha a impressão que era um tema que nunca esteve tão em alta, mas como bom cientista de dados que eu acredito que eu seja, fui atras de dados quando tava construindo essa apresentação, e de fato minha intuição tava correta, a tendência de pesquisas do termo MLOps é positiva. A máxima histórica foi atingida no fim do mês passado e assim como o mercado de ações vem sofrendo uma correção ao longo das últimas semanas, o que demonstra com bastante certeza a importância do tema, a gente para de pesquisar MLOps e o mercado cai, isso não é coincidencia. Não vou me aprofundar nessa teoria agora, não é o objetivo, da palestra a gente pode deixar essa conversa para o almoço.
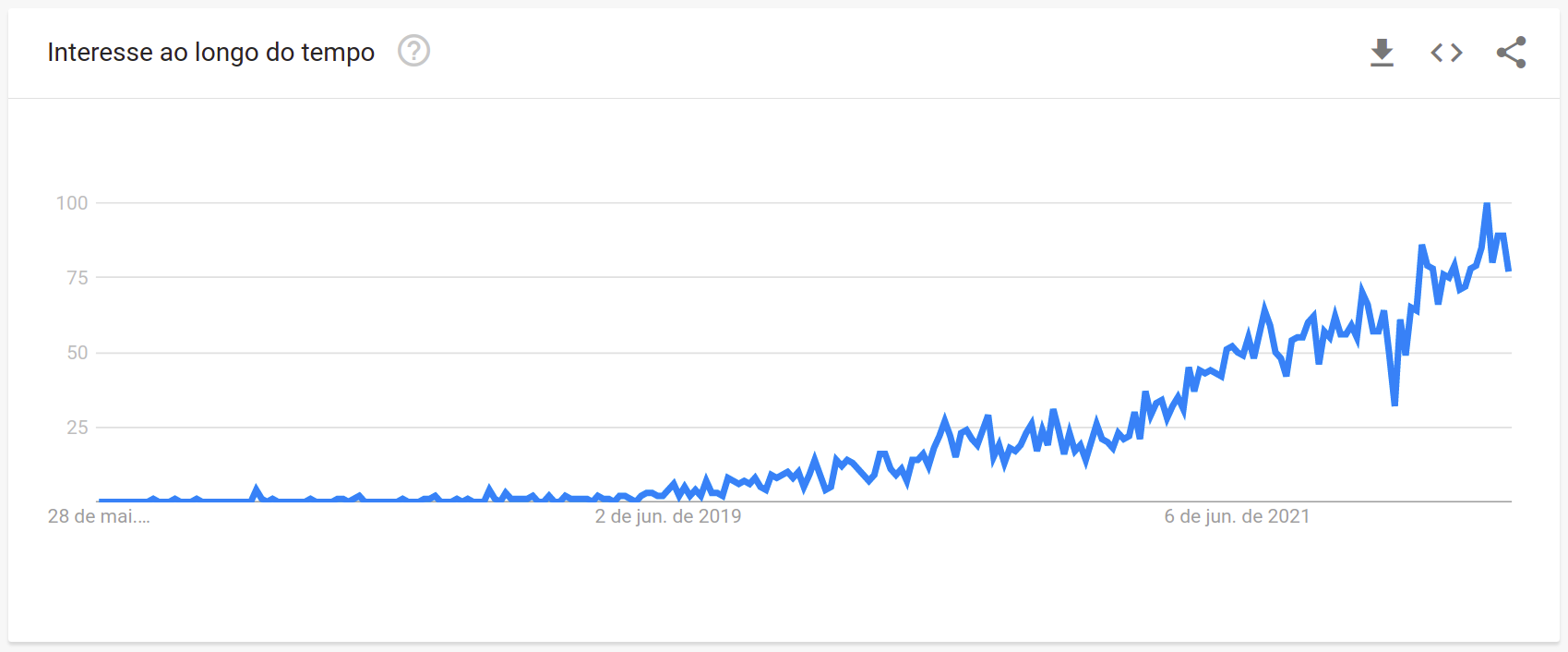
Enfim, tirando a piadinha infame, MLOps está sendo o buzzword de quem superou o buzzword “inteligência artificial e machine learning e etc.” Mas, assim como inteligência artificial, é um assunto que que tem motivo para ser falado, e o objetivo dessa disciplina é tornar os cientistas de dados capazes de mais do que só desenvolver modelos em notebooks, é criar modelos modelos e entregar um processo robusto e que permita que os modelos evoluam ao longo do tempo. O desafio da ciência de dados, pelo menos no mercado, porque na academia os objetivos são um pouco diferentes, não é criar criar modelos de machine learning, é criar soluções que entram em produção, fazem parte do fluxo da empresa em que tão presentes e agregam valor, aí de preferência é claro utilizando machine learning.
Apresentação de ferramentas
Eu vou trazer aqui rapidamente as ferramentas que vamos usar nessa demonstração, eu não vou me ater a explicar profundamente o funcionamente delas, primeiro porque eu acho que não vai ser absorvido, e segundo porque a documentação faz isso muito melhor que eu poderia fazer. Vou trazer uma sugestão e um overview de uma arquitetura, é uma proposta e aí cabe a cada um adaptar para um fluxo que atenda a necessidade de vocês.
Esse é um diagrama do que eu espero obter:
MLflow
O MLflow é uma plataforma open source para gerenciamento do ciclo de vida de um projeto de machine learning, o objetivo dessa ferramenta é auxiliar no controle das experimentações, garantir reproducibilidade dos resultados, fazer deploys e servir como um repositório central de modelos.
Essas funcionalidades são empacotadas em componentes da bibiblioteca, que são:
- MLfLow Tracking
- MLflow Projects
- MLflow Models
- Mlflow Registry , Nessa POC que iremos contruir vamos utilizar apenas os componentes de Tracking e Registry, que vão nos auxiliar com o comparativo entre modelos e serving do melhor entre eles.
Pipelines do scikit-learn
São uma sequência de transformações que culminam em um estimador, ou seja, são os passos de limpeza e feature engineering que queremos aplicar nos dados de input antes de passar para o modelo e o próprio modelo que queremos utilizar encapsulados em um unico objeto.
Os transforms podem ser praticamente qualquer objeto do módulo de pre-processing do scikit-learn, como:
- LabelEncoder
- MinMaxScaler
- OneHotEncoder
- OrdinalEncoder
- PolynomialFeatures
- StandardScaler
- etc…
E também podem ser transformações próprias das regras de negócio de vocês, ou mais comum que isso, características do dataset que vocês estão trabalhando onde precisamos extender a funcionalidade dos transformadores padrão. O requisito que uma Pipeline impões para esse objeto é que ele tenha os metodos .fit() e .transform().
Já a ultima camada de um Pipeline é composta por um estimador, assim como o transformer esse pode ser um objeto do próprio scikit-learn ou qualquer implementação externa desde que possua o método .fit().
API
Essa é a última parte da nossa arquitetura, e é a interface do modelo com as consultas que serão feitas pelos nossos clientes, o framework utilizado é totalmente a gosto do programador, aqui eu vou demonstrar utilizando o FastAPI não só porque parece que ninguém mais lembra que existe Flask, mas também porque os docs built-in vão facilitar na demonstração serviço em funcionamento.
Mas basicamente nossa API terá duas funções, buscar o modelo que está no repositório de modelos do MLflow, e atender as requests dos clientes que chegarão com dados crus, transformar esses dados e retornar um prediction.
Bora para o código
Criando a pipeline no scikit-learn
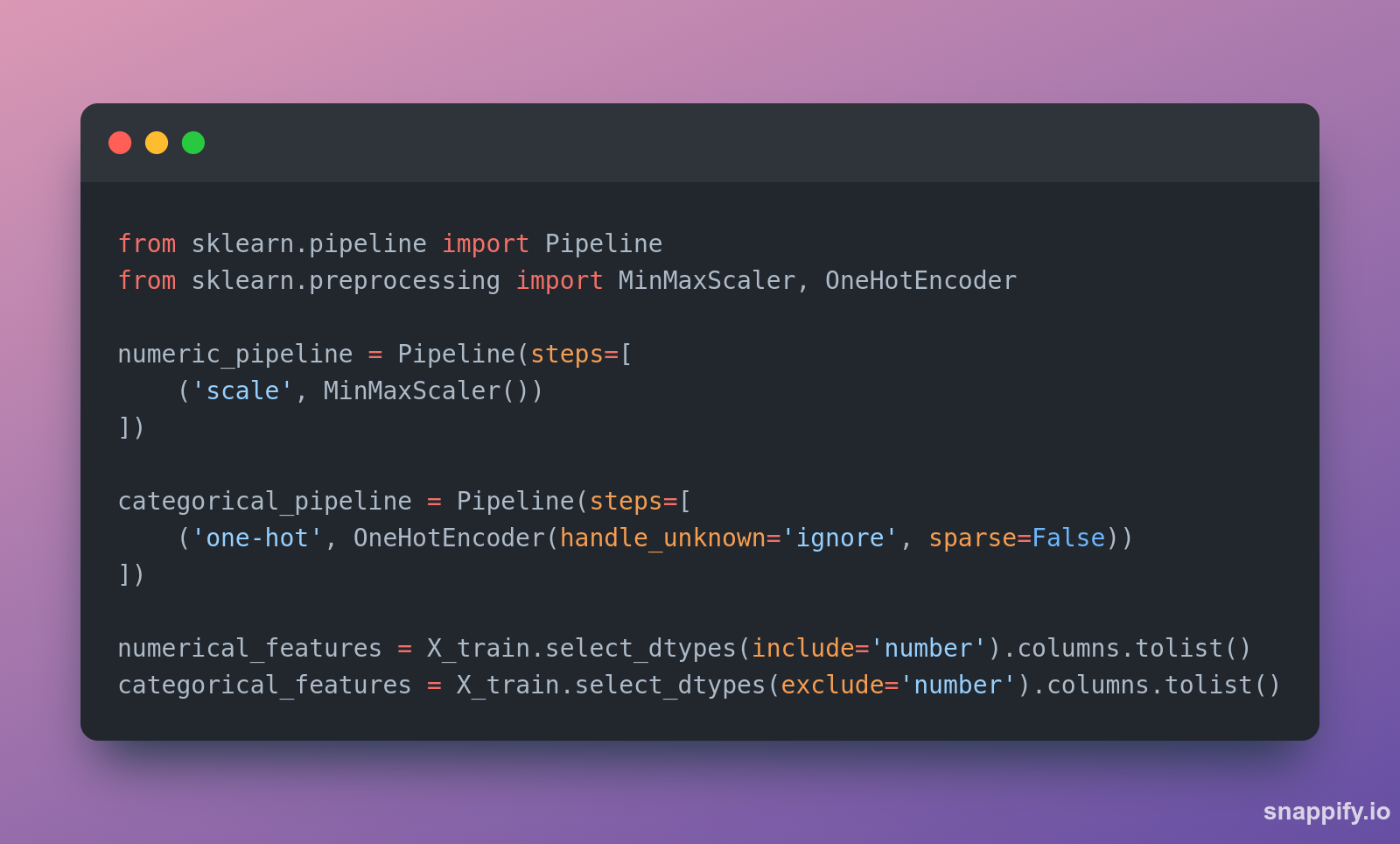
Assumindo que a gente já tem um dataset carregado, exploramos os dados e chegamos na conclusão de qual transformações e limpezas realizar, criamos o pipeline que vai realizar esses steps para nós
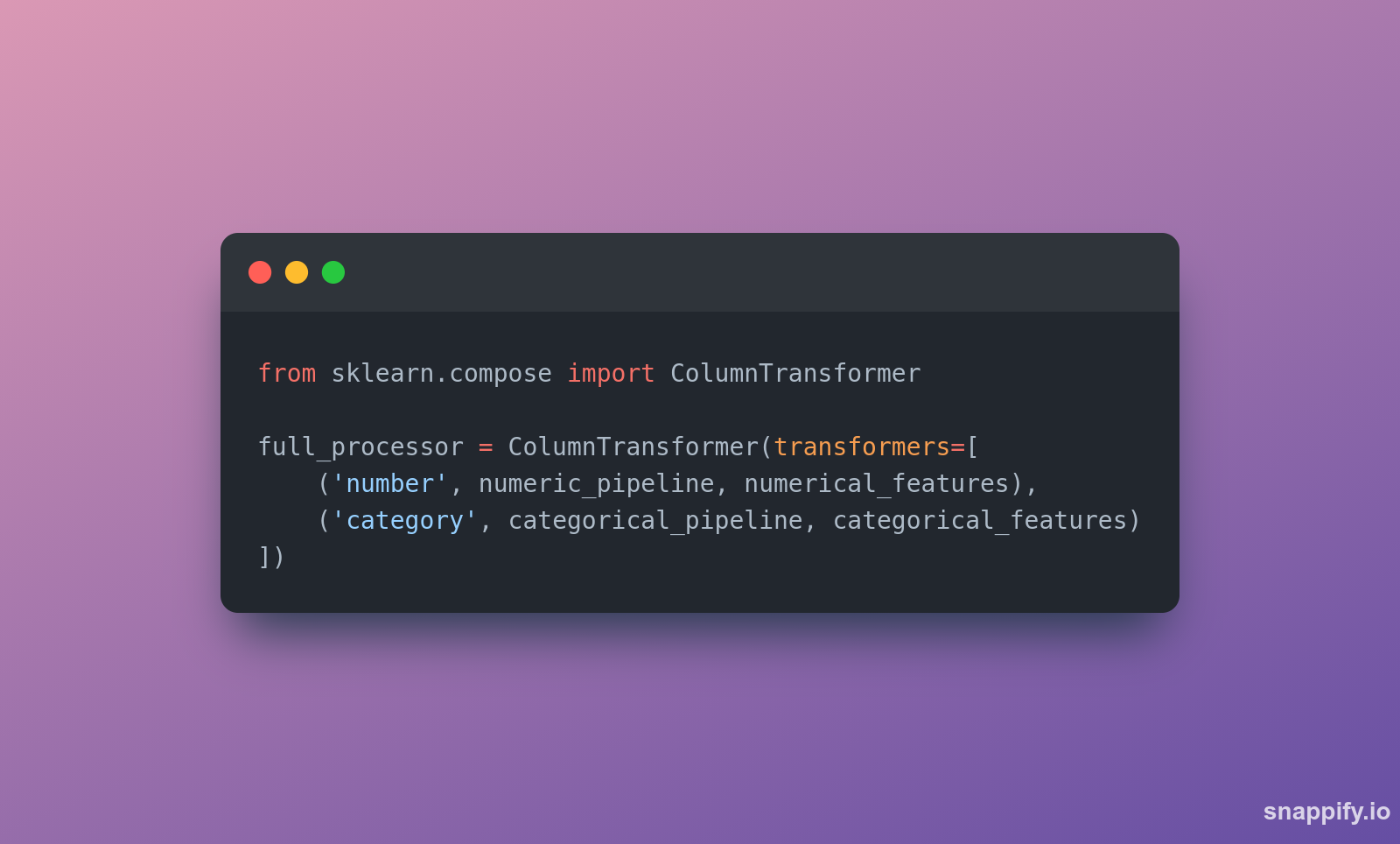
O segundo passo é montar é dizer ao scikit-learn em quais colunas aplicar os pipelines que criamos, para isso usamos o ColumnTransformer, é um objeto que mapeia um pipeline para um determinado conjunto de colunas
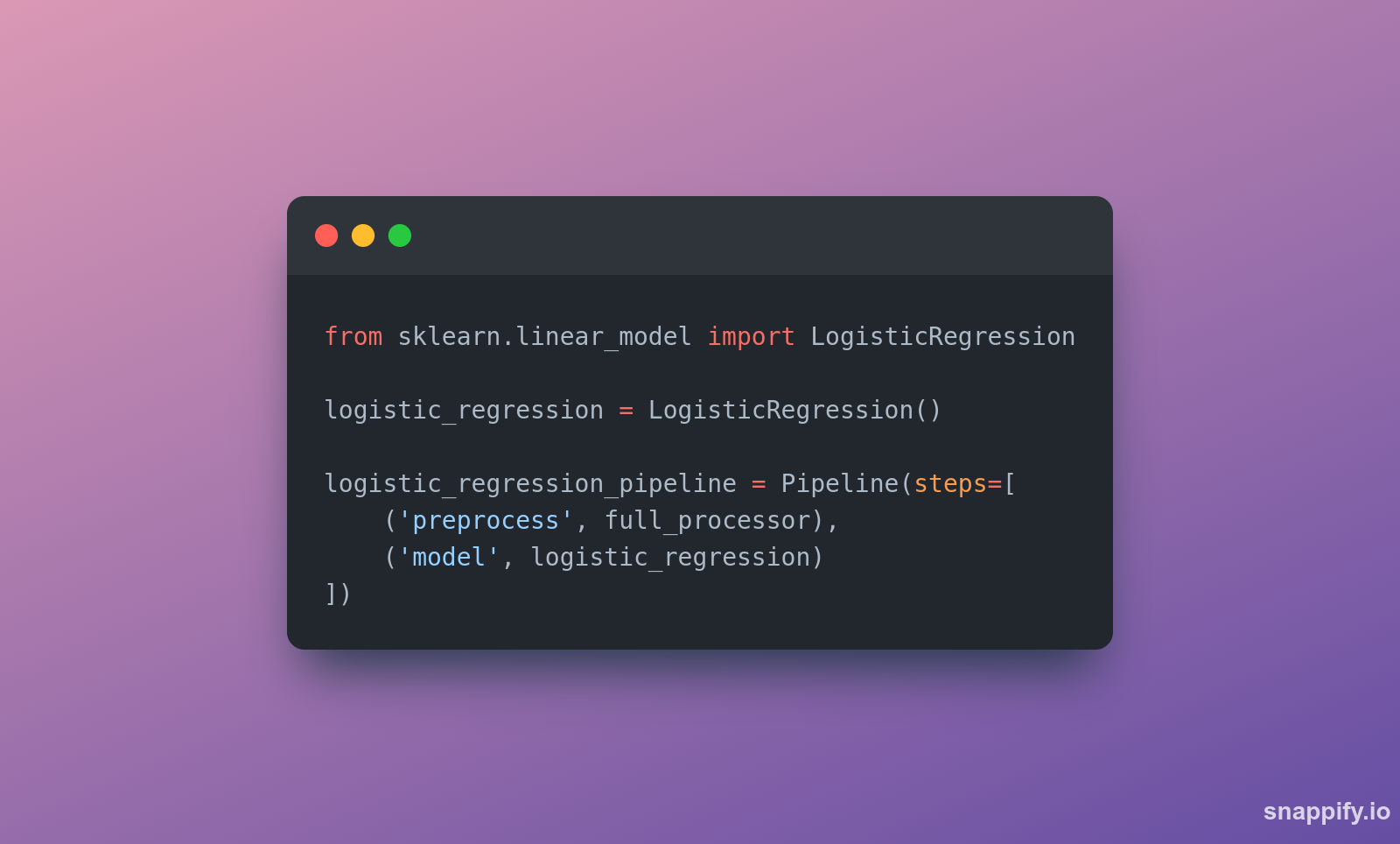
E por fim a gente adiciona um estimador no pipeline final. E o que temos é um pipeline, que determina quais colunas irão passar por quais transformers antes de serem inputadas no estimador.
Configurando o MLflow
Beleza, agora que já temos qual será o processo pelos quais os dados de treino passarão, vamos configurar o MLflow para receber conseguir guardar esse modelo num repositório remoto.
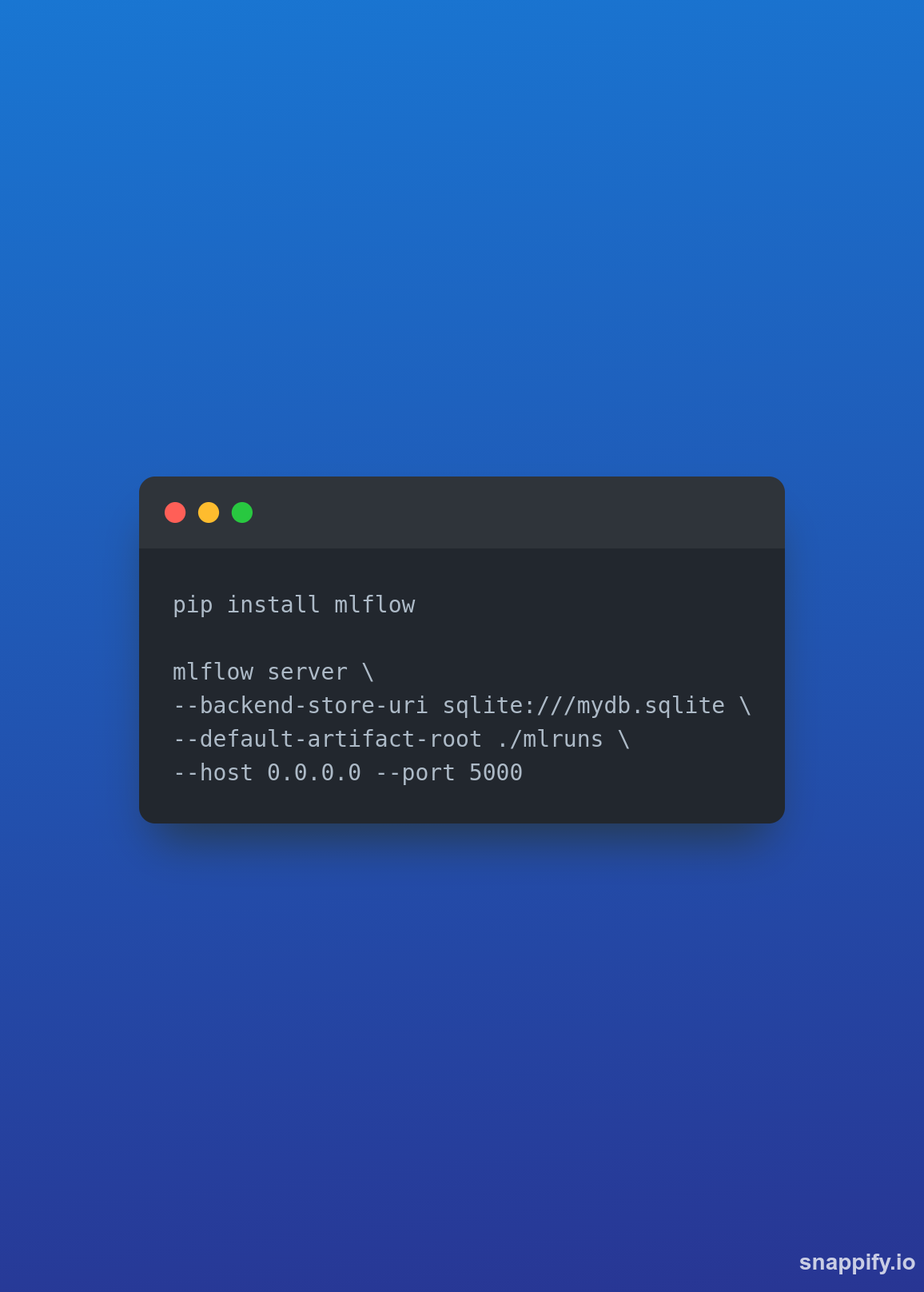
Voltar ao notebook e rodar o .fit() da pipeline
Pronto, a gente construiu toda nossa pipeline e agora vamos utilizar o autolog do mlflow para capturar o treino do modelo, que irá salvar os parâmetros utilizados, as métricas de avaliação padrão obtidas e o pipeline em si.
UI do MLflow
Agora eu vou voltar para o mlflow, mas dessa vez nós vamos explorar a UI.
E na API?
basta incluir as seguintes linhas para obtermos o objeto do mlflow e conseguirmos usar ele dentro da nossa api

e agora ajustamos na rota para recebermos um dicionario no formato chave e valor que será transaformado numa linha de um pandas do DataFrame:
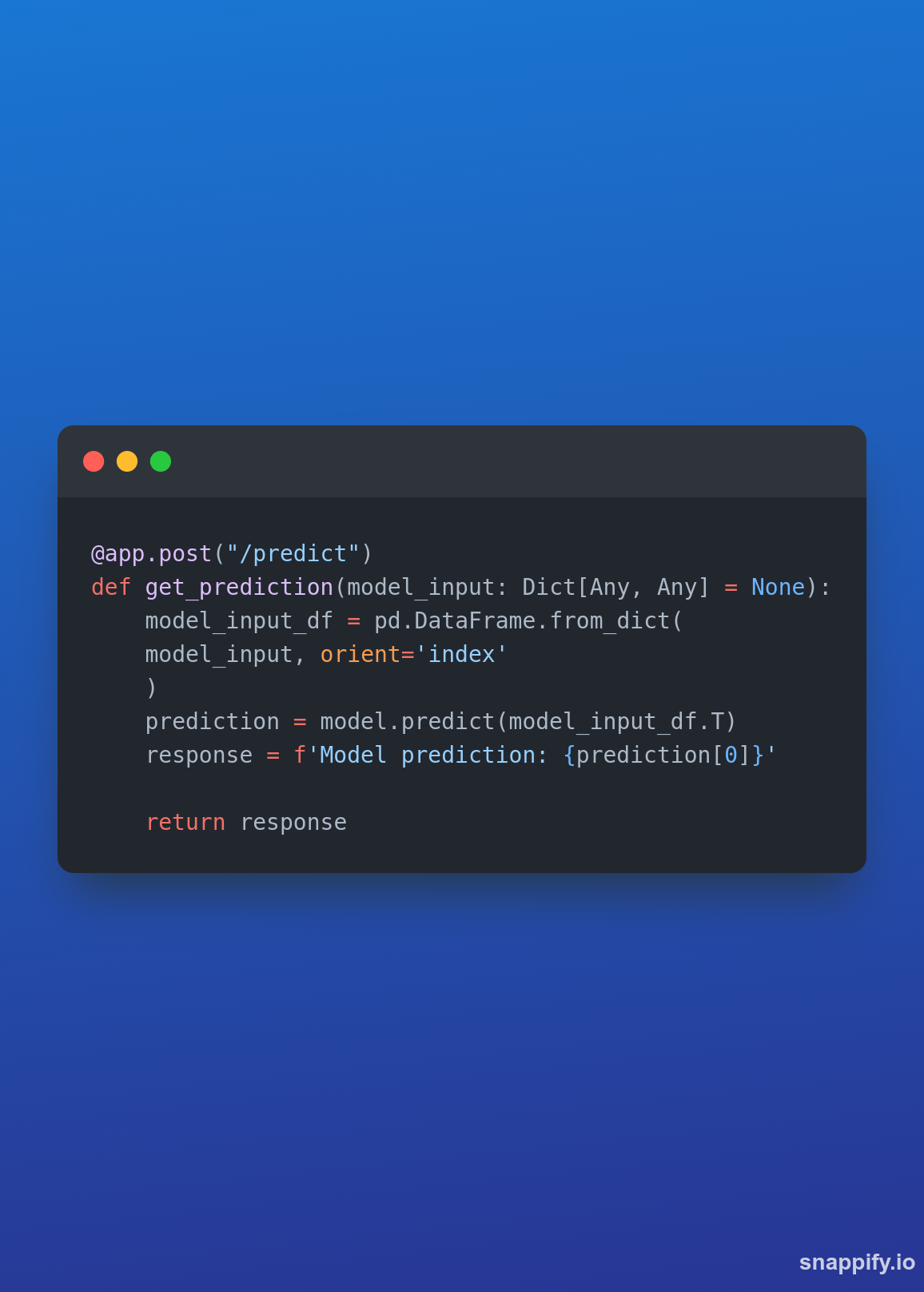
E pronto, agora sem precisar escrever os processos de feature engineering tanto na modelagem quanto na criação da API, nem ficar passando .pkl de um lado para o outro para disponibilizar os modelos, temos uma arquitetura sólida, flexível e resiliente.
References
https://madewithml.com/ https://fastapi.tiangolo.com/